SYNOPSIS
OPTIONS
DESCRIPTION
By default, two columns of rhythmic information are stored at the start of the note array: (1) the measure number in which the sonority occurs, and (2) the starting beat position of the sonority within the measure. Each **kern part should be monophonic by itself; otherwise, only the primary (left-most) notes in a part will be extracted. Here is an example run of the notearray program with no additional options being used: 
In this example, the first column of output data shown on the right contains the measure number in which the notes on each line were extracted. The second column list the beat within the measure at which the notes occur. Then there are four columns (one for each input **kern spine) which stores the pitch information of each spine. The default numbering system used in the output data is the base-40 system (described below). In this case the number 128 means D3, or the note D a seventh below middle C. When a note value is negative, this indicates that the note is being sustained from a previous sonority within the score. Note values of 0 represent rests. Pitch numbering methodsEach of the three output one-dimensional numbering methods for pitches is based on chroma (or pitch-class) and octave values. The base value indicates the octave number, and the chroma can be extracted from the modulo, or remainder:
chroma = number % base
chroma = 60 % 12 = 0 For base-12, the default octave for middle C is 5 so that it matches MIDI key numbers, while in base-40 and base-7, middle C's octave is set to 4 so as to match the ISO labeling of octaves. If the input data contains very low notes, then some pitches will incorrectly be assigned to negative octaves (and 0 may represent a pitch as well as a rest). To avoid these cases, use the -o # option to transpose the integer values for pitch up the specified number of octaves to avoid negative octaves in the output data (since negative values are intended to represent sustained notes).
Base-40Base-40 is a method of encoding diatonic pitches with accidentals up to double sharps or flats. The base-40 chroma for pitches can be built up from the property that a minor second is a difference of 5 between pitch numbers in the base-40 system, and major seconds are a difference of 6. The C chroma value is set to the value 2 rather than 0 so that the octave values for C♭ and C♭♭ remain in the same octave as C♮ just above these pitches when using division by the base to extract the octave number. Here is a complete table of the base-40 chroma, using C=2 as the reference:
To calculate an absolute pitch such as G4 (The G above middle C), multiply the octave by 40 and add the chroma value for the G pitch-class: Note that base-40 pitch representations preserve chromatic alterations of diatonic pitch-classes (up to double sharps/flats). Therefore F♯4 (180) is not in the same as the base-40 pitch G♭4 (184). A useful property of the base-40 system is that the difference between pitch numbers in the base-40 system represent one-to-one mappings with diatonic intervals:
As an example, consider the interval between E4 (174) and C4 (162) which is 174-162 = 12, representing a major third according to the table shown above. All intervals can be constructed by observing that major seconds are 6 and minor seconds are 5, so note that a major third, consisting of two major seconds, is 6 + 6 = 12. Below is an example segment of music with the pitches labeled in the base-40 system. Try subtracting values and comparing the results to numbers in the base-40 interval-class table above.

Base-12Base-12 numbering of pitches assigns 12 notes to an octave as on a standard musical keyboard. The values output by the notearray program match the values used as MIDI key numbers, where middle C is assigned to be 60, C♯4/D♭4 to 61, D4 to 62, etc. This makes the octave value for middle C up to the B a major seventh above to be one higher than for the base-40 or base-7 outputs from notearray at 5, compared to 4 for the other numbering methods' middle octave. Using the option "-o -1" will make the base-12 numbers match the same octaves as base-40 and base-7; or conversely, you can use "-o 1" for base-40 and base-7 outputs so that the middle-C octave is 5 to match that of the base-12 output.Base-12 chroma do not map one-to-one with diatonic-based pitch-classes. For example, C♯4 and D♭4 belong to different diatonic pitch-classes, but they have the same base-12 pitch value (represented by the number 61).
Essentially, representing pitches in base-12 is equivalent to stripping off the accidental information of base-40 diatonic values. Or another way of stating this is that you can unambiguously map base-40 values to base-12 values, but not the other way around. Here is the same example segment of music, with pitches given base-12 numbers:
 Base-7Base-7 is a representation of the pitches in diatonic form without any accidental alterations. For example, C♭4, C♮4, and C♯4 are all represented by the number 28 = 0 + 4 * 7, where 0 is the base-7 C chroma, 4 is the octave and 7 is the base. Base-7 values are another method of stripping accidental information off of base-40 values.
Here is the same example segment of music, with pitches given base-7 numbers:
 Note namesThe -k option can be used to include a column of note names before each numeric column describing the notes. The --quote option may be used to enclose the kern pitch name in quotes. The --no-tie option can be given to hide tied note information on the **kern note name. The -T option can be used to mark a tie-start ([) and tie-end (]) on a note which only exists on a single row (i.e., it does not sustain past the current row). Output formatsThe output note array data can be formatted in three styles. The default output style is suitable for loading into matlab, where the data represents a matrix with tab characters separating values in each row. The -H option will generate data in a proper Humdrum file format. The --math option will format the output data into a form which can be read into Mathematica.For automatic identification of each column's data type, the -c option can be specified. This will insert a row of integers at the top of the array which describes the data stored in each column:
An index column (generated with the -i option) will not have a type number, and all rows in the index column will represent line indices for that row of the array. Typically the index column is not needed by processing program which can count the lines of the array by themselves, and the index column is more useful for human readability of note index values. In the following example, the -c option adds the column description number, and the -I option suppresses the textual comment describing the column type. The -C option can be used to suppress echoing any comments in the input data into the output, generating purely numeric data:
MatlabThis is the default output format. Each data row consists of a constant number of values (unless multiple input files containing different numbers of parts are given) which can be loaded into a matrix in matlab or octave with the following command: load('data') where "data"
is the name of the file in which the output data is stored, plus the
extension ".mat". Alternatively, if the filename is
data.dat or with some other extension, then load with
the command load('data.dat').
The loaded data will be stored in a matrix with the same name
as the file (without the extension)
which can be further processed, such as with the size() function which
reports the number of rows and columns in the matrix:
octave:2> size(data)
ans =
190 5
The matlab-style note array can be loaded into python with code like this: HumdrumSpecifying the -H option will format the output data as a Humdrum file which can be further processed with Humdrum tools.
Note that the two commands in the following example will produce the same results, where rid is a standard Humdrum Toolkit program which is removing interpretations and global comments, leaving only data lines:
MathematicaFor generating data which can be loaded into Mathematica, use the --math option. When using the --math option, you must also specify a variable name for the array in the output data. For example:
Notice that the text string after the --math option name (twobars) was used to set the name of the data in the above output. The -a option was used to add an additional column of information showing the absolute beat position within the score of each data row (the score duration since the start of the music). The -m option was used to display pitches in base-12 (MIDI key number) format. The Mathematica output data can be loaded into Mathematica using the Read[] function: SetDirectory["C:/wherever"];
Read["data.ma"]
An example application of this data would be to load into Mathematica, and then generate piano-roll notation from the data with the following function: which generates this plot, with pitch on the y-axis and score duration (in quarter notes) on the x-axis: 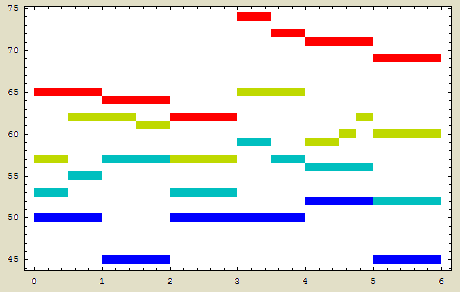 SetDirectory["C:/wherever"]; variable = Import["file.dat", "TSV"];When multiple input files are processed by notearray, the Mathematica-formatted output will contain a nested list of data for each input file. Position information columnsFive types of positional information can be given on the left side of the note array. By default the first two columns of data for each row in the array are the measure number and the starting beat position of the sonority within the measure. These columns can be suppressed with the -M and -B options, respectively. Use both options to suppress both columns of information, or use the -N option to suppress both columns of positional information, so that only note columns are output:
Two additional informational columns are also available. The -l option will display the line number in the input Humdrum data from which the sonority was extracted. This is useful when linking analysis data back to the orignal score. The -a option will display the absolute beat position which is the duration between the start of the music and the beginning of the sonority. All five information columns can be displayed by using the -A option, which is equivalent to giving the -l, -a and -D options. Information columns will always be displayed in a fixed order: (1) line number in original file, (2) measure number, (3) metric position, (4) absolute beat position, and (5) row duration.
Using the -i option will cause the first column in the array to display the line index for each row of the array. By default, the indexing starts at 0, but can be started at 1 by using the -1 (numeral one) option. Other positive starting index values can be specified with the --offset # option, where # is a positive integer. This option is useful when concatenating individual arrays together into a larger array. Here is a summary of the options which can be used to display or suppress position information to the left of the note columns:
Rational values for beat positionsBeat and absolute beat positions are displayed as floating-point numbers by default. If you need to avoid round-off errors for tuplets, you can use the -r option to display these values are rational numbers. In the following examples, numbers such as 1.5 in the beat column are converted into numbers such as "1+1/2".
To display the beat values as rational fractions and not as a compound integer value plus fractional part, use the -f option. This will convert 1.5 into "3/2" rather than "1+1/2":
Parallel indexing arraysThe note data consists of rows of sonorities which can be composed of note sustains (negative integers), note attacks (positive integers) and rests (zeros). In order to navigate melodically through the columns, several options can be used to store indices of the current, previous and following note within each note column:
With the information in these index column, the duration of each note can be calculated from a simple algorithm: The duration of the current note is the difference between the absolute attack time of the next note minus the absolute time of the attack of the current note. See the -e option for details on determining the duration of the last note in each note column.
Note that index values of -1 are used to indicate that there are no notes before the first note in the column (for --last data), and no notes after the last note in the column (for --next data). When multiple input files are given to the program, the next and last data columns do not span multiple inputs, so -1 indices will be found at the boundaries. However, the non-negative index values will increment continuously between multiple inputs. Comments and reference recordsBy default all global comments and reference records will be echoed into the output data as comments. These comments can be suppressed by using the -C option. To suppress global comments and only echo bibliographic (reference) records, use the -b option. For output formats other than the Humdrum file format (generated with the -H option), an initial comment line before the first data line describing each data column will be given unless the -I option is used to prevent its printing.Ending restsBy default, the notearray program generates one row in the output array for each data line in the input Humdrum file. The duration of each row can be calculated from the information column produced by the -a option (the absolute beat position for the row). The difference between each absolute beat position is the duration for the sonority of each row. However, the duration of the last row cannot be calculated without knowing when the last sonority is released. Therefore, the -e option can be used to generate a rest sonority after the end of the last sonority in the score to allow calculating the duration of the last row in the note array.
In this example, the extra row in the output data allows the duration of the last sonority to be determined (6 - 4 = 2 beats). And the duration of the entire score is the absolute beat position of the rest in the last row (6 beats). Double-barline restsA row of rests can be inserted in the output data when double barline occur in the score by specifying the --double option. This is useful to separate phrases in certain types of music.Sustained sonority suppressionUsing the -S option will suppress all output lines which contain only sustained notes. This is used to generate more parsimonious data.Beat durationThe -t option can be used to specify the duration of beats within the music. For example music in 6/8 will automatically be assumed to be in a compound meter with the beat equal to the dotted quarter note ("-t 4."). However, in certain cases the beats might instead be defined on the eighth-note level ("-t 8").
Multiple input filesThe following options work when multiple input files are given to the notearray program.Measure numbersThe -mo option can be used to generate unique measure numbers in the output data when multiple files are given as an input. The -mo option is useful for keeping track of the source file in the output data when there are multiple input files. The option takes an integer argument which is the an increment in the measure number offset for each input file. For example if --mo 1000 is used, then a value of 1000 will be added to the measure numbers of the first file's output, 2000 to the second file's output, and so on. This allows the originating file to be identified in the output data (provided in this case that no file contains a measure number greater than 1000, in which case the increment should be set to 10,000).
Absolute beat valuesWhen multiple files are input, the absolute beat values generated by the -a option will continue across multiple files. To rest the absolute beat values for each input, use the --sa (--separate-absolute) option. Note in the following example that the third column (absolute beat) in the first output reset to zero at the start of the output for the second input file, while in the second notearray output starts the absolute beat position of the second file at the ending duration of the first file.
EXAMPLESConstant-duration sonoritiesTo generate note arrays with a constant duration for each row, pre-process the Humdrum data with the standard Humdrum Toolkit program timebase. The timebase command is used to insert null record rows into the original data so that a constant spacing at the given rhythmic duration is given to each line of data.In the following example, the smallest rhythm is a sixteenth note, so the timebase rhythm is set to 16 which makes each line of data represent a sixteenth note.
Bach choralesHere is a demonstration of how to generate data for 370 Bach chorales in a single step:
notearray --mo 1000 --mel --sep -ali *.krn > bachchorales.txt
The output file contains 30279 sonorities from all of the chorales, with a total duration of 19814 quarter notes. The --sep option is used to place a comment line between analyses from different input files. The "--mo 1000" option is used to store the file name in the 1000's digit of the measure numbers in the output data. Separating sonorities into beats/offbeatsA simple method of separating sonorities occurring on the beat or off-beat can be done using the hgrep program to select tokens in the **beat column depending on whether they contain a decimal point or not. Sonorities on beats will have an integer beat position without a decimal point, while sonorities on offbeats will have a beat position containing a decimal point and a fractional part.Extracting sonorities off of the beat:
Extracting sonorities on the beat:
Extract sonorities on the beat, including sonorities containing only sustained notes:
Count the pitch classes in sonorities on offbeats:
Count the number of pitch classes attacked on offbeats:
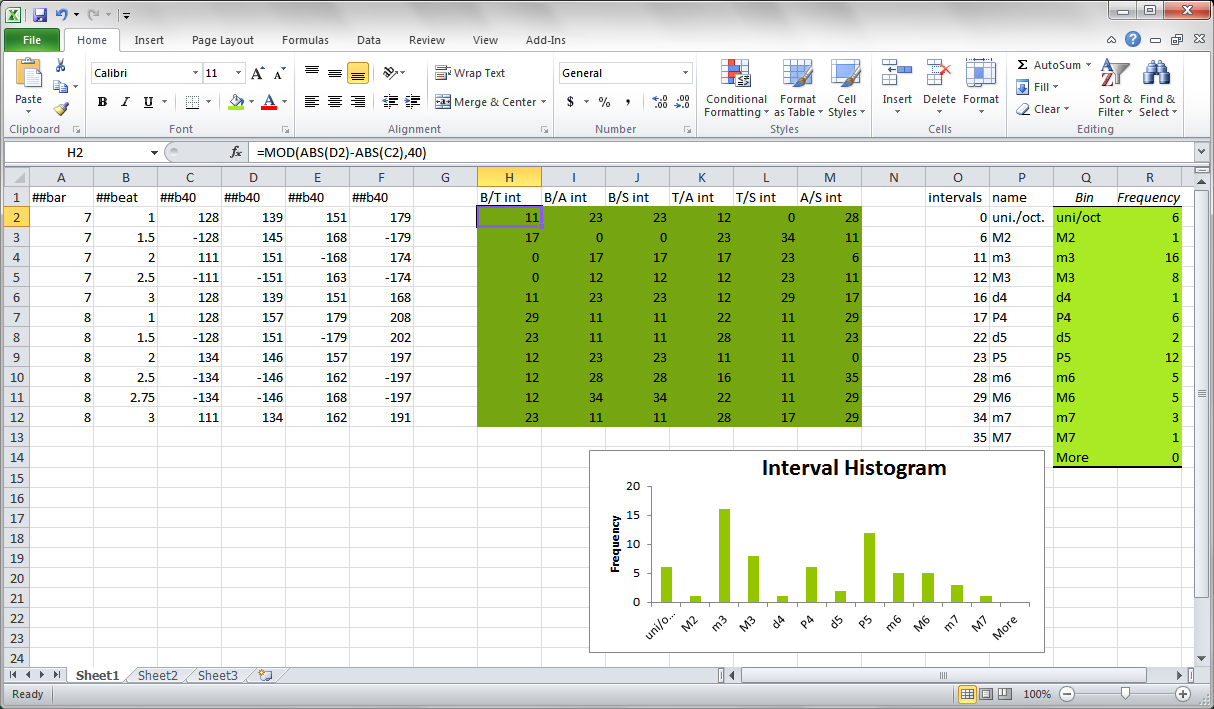
Using data in MS ExcelThe output from notearray can be loaded into MS Excel as a tab-deliminated text file (either the default matlab-style output, or the Humdrum output generated by the -H option). In addition, the output data can be copy/pasted from text editors/word processors which preserve tab charcters, such as the following textarea box on this HTML page:Below is a screenshot of the above data loaded into an MS Excel spreadsheet (xlsx, xls). The intervals between each voice are shown in the dark green box in the middle, with a histogram calculated in the light green box on the right which is plotted underneath. Note that the hightlighed cell (H2) contains the equation "=MOD(ABS(D2))-ABS(C2),40)" which is the interval between the tenor and bass voices (collapsed to less than an octave). Columns O and P contain a mapping of the interval value to a more musical name for the interval, with 11 being a minor third (m3). Click on the image for a larger view.
More example usages of the notearray program are available on the notearray examples page
program file.krnIt can also read the data over the web: program http://www.some-computer.com/some-directory/file.krnPiped data works in a somewhat similar manner: cat file.krn | programis equivalent to a web file using ths form: echo http://www.some-computer.com/some-directory/file.krn | program Besides the http:// protocol, there is another special resource indicator prefix called humdrum:// which downloads data from the kernscores website. For example, using the URI humdrum://brandenburg/bwv1046a.krn: program humdrum://brandenburg/bwv1046a.krnwill download the URL: Which is found in the Musedata Bach Brandenburg Concerto collection. This online-access of Humdrum data can also interface with the classical Humdrum Toolkit commands by using humcat to download the data from the kernscores website. For example, try the command pipeline: humcat humdrum://brandenburg/bwv1046a.krn | census -k SEE ALSO
LIMITATIONS
DOWNLOAD
The source code for the program was last modified on 12 Nov 2013. Click here to go to the full source-code download page. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||

