SYNOPSIS
OPTIONS
DESCRIPTION
For example, the humcat program can be used to extract embedded Humdrum data to standard output:
The humcat program can also be used to interface to the standard Humdrum Toolkit programs:
All PDF files downloaded from the kernScores website contain an embedded Humdrum file (if the PDF file has a companion Humdrum file), such as this one used as an example in a later section below. Embedding a Humdrum file into a PDF fileThe basic command structure for creating a PDF with embedded data is:
humpdf -p input.pdf file.krn > output.pdf
The -p option specifies the original PDF file to which the
Humdrum file will be embedded. Results of the humpdf are sent
to standard output, so redirect the results to a file.
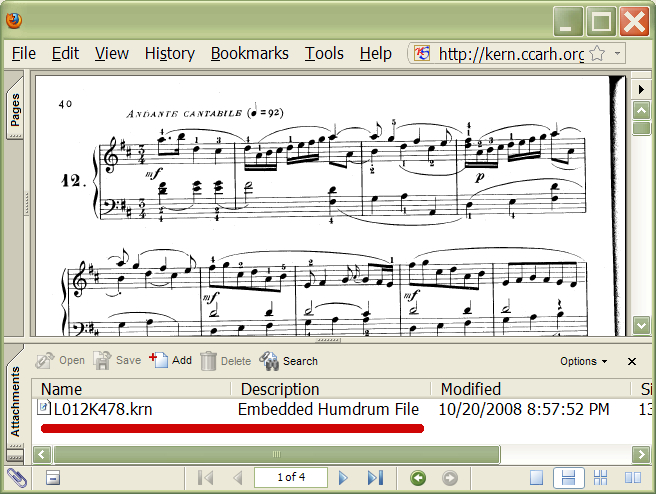
Viewing/Adding Embedded files in Adobe ReaderEmbedded files can be viewed as "Attachments" in Adobe Reader. Below is an example view of the Adobe Reader plugin in Firefox with this file. The paper clip icon at the bottom left indicates that the PDF file contains an attachment. You can view a list of the attached files by clicking on the "Attachments" tab on the left side of the viewer. In versions of Adobe Reader which do not display an "Attachments" tab, the attached files can be viewed by clicking on the paper clip icon instead.
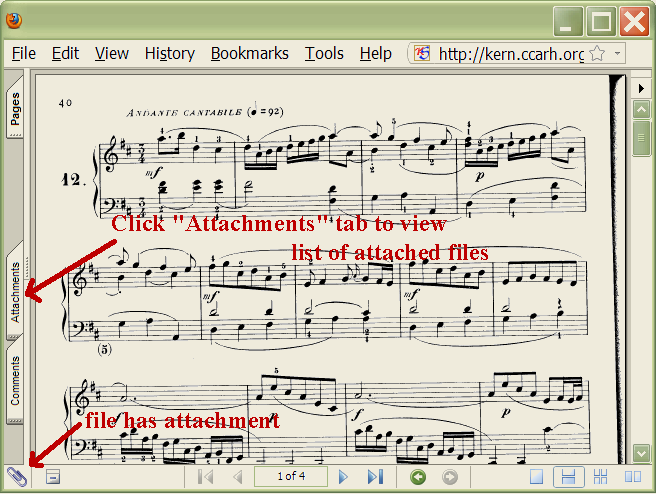
After displaying the attachments, you should see a file listing
underneath the main PDF page viewing window. In this case there is one
file called L012K478.krn. Also notice that the
Description of the file is "Embedded Humdrum File". This description
string is required in order for the Humdrum Extras programs to recognize
the embedded file as a Humdrum file. You may also embed files using Adobe
Reader by clicking on the "Add" icon above the attachment Name field.
If you want Humdrum Extras programs to treat the attached file as a Humdrum
file, then you must add the description string "Embedded Humdrum File".
That string can be followed by or preceded by any other text in the
description string.
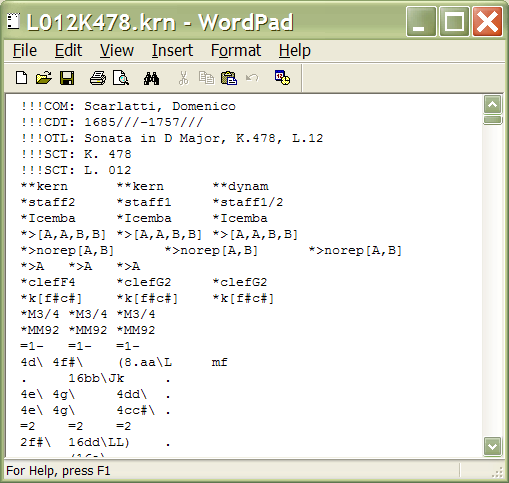
You can double-click on the name of the attached file to view it.
On Windows computers, you will have to first associate a program with
files that end in .krn. To do this in Windows, right click on a file
ending in .krn in the regular Windows File Explorer, then choose your
favorite Humdrum IDE program from the list of programs that appears.
Here is what it looks like after opening the attached file into WordPad:
Embedding dataHere is an example demonstrating how to embed a Humdrum file into a PDF file of the musical notation created from the Humdrum file:
hum2abc middlec.krn > middlec.abc
abcm2ps middlec.abc -O=
ps2pdf middlec.ps
The final file: middlec.pdf which is used to
embed the original source file:
humpdf -p middlec.pdf middlec.krn > middlecembedded.pdf
Notice that the input PDF file does not contain an embedded file, while the output file does. Technical notesPDF files are composed of a series of segments called indirect objects. Each indirect object starts with two numbers: (1) the object number, and (2) the generation number (which is typically set to zero). Following these two numbers is the string "obj" followed by the content of the indirect object, ending with the string "endobj": Above this basic file organization comes a header. The first line of the file must start with the string "%PDF-" followed by the PDF standard to which the file conforms. In the following example, PDF specification 1.4 is being used. The second line of the file should contain a comment line which has at least 4 bytes of data containing high-order ASCII data (bytes with values greater than 127). This is a hack used to force certain pieces of software or operating systems to process the file as binary data rather than text data (newlines of the different Windows/Apple/Unix formats can exist in the file, and reading the file as text data may incorrectly translate these formats to the native format of the local computer). At the bottom of a PDF file, the last line is required to be "%%EOF". On the penultimate line, the byte offset of the most recent cross reference table is found; and on the line before that the string "starxref" is required. In this case the value 192 means to go to the 193rd byte in the file (or 192nd byte when counting the bytes starting at 0). At that point you will find a cross reference table which starts with the string "xref". Following the "xref" string are two numbers: (1) The starting indirect object number being listed below, and (2) how many indirect objects are listed in sequential order after the first one. In this example, the string "0 5" means that the first object is number 0, and there are 4 indirect objects entries after the first one in the list below. Indirect object 0 is a special object which functions like a NULL pointer in C. Each object entry in the cross referecne table consists of a line with exactly 20 characters. The first ten characters are digits which gives the byte-offset value for the start of the indirect object. For example, object 1 starts at byte offset 16 (the 17th byte in the file). Offsets smaller than a billion are padded with zeros. Next comes exactly one space, followed by five digits which indicates the generation number (typically set to zero), then another space, then either the character 'n' (meaning "iN use") or 'f' (meaning a (Free [unused] object), followed by a two-character newline (0dh 0ah in hex notation). After a listing of object offsets is given, another set of entries can be given, starting with the first object number and a count of how many objects in the seqential list. The trailer which follows the xref section gives a few important pieces of information in the form of a dictionary (which is a set of associative pairs of keys and values surrounded by double angle brackets: <<...>>). A typical trailer is required to have an entry called /Size and /Root, and may have other optional entries.
The /Size entry's value of 5 means that there are a maximum of five indirect objects in the PDF file (as might be suitable for the above example PDF with objects number 1-4, plus the 0 object). The /Root entry's value "0 1 R" is a reference to indirect object number 1 (generation 0). The Root object is the catalog dictionary of the PDF and behaves like the root of a file system. Incremental updateThe humpdf program embeds data files using a feature of PDF files called incremental updates. With this method of chaning a PDF file, the original contents of the file can be recovered from the modified file if necessary. All new objects are appended to the previous PDF file's contents, as well as an updated version of any indirect object from the previous file contents.Here is the basic structure of the middlec.pdf file with the compressed data for the page description removed: Looking at the trailer, the root object is number 1. Object 1 contains three entries in its dictionary: /Type, /Pages, and /Metadata. The /Catalog value of the /Type entry is required for the root object, and the /Pages entry contains a pointer to indirect object 3 for a list of the pages in the file. Going to object 3, you will see there is a list of pages, one page which is contained in object 4. Object 4 gives a basic descriptive informatnion for the page, and in particular the contents for the page which is contained in object 5. Object 5's content is compressd, so it has been removed from the above example text. To embed data files in a PDF, there is a analogous entry to /Pages
in the Root dictionary called /Names. The /Names entry in the root
dictionary points to another object which contains an entry
called /EmbeddedFiles which in turn points to an indirect object
containing a list of embedded files.
[...]
BUGS
DOWNLOAD
The source code for the program was last modified on 6 May 2010. Click here to go to the full source-code download page. |